
Should you parallelize or serialize disk access in node.js?
I was making a program that loads an arbitrary directory tree of images, gets their metadata and displays them on screen. The question cropped up, how do I do this in the most efficient manner possible?
In a "naive" implementation, I could just await every single async call. Something along the lines of:
async function processDirectory(path) {
const files = await fs.readdir(path);
for (const file of files) {
const filePath = libPath.join(path, file);
const stats = await fs.stat(filePath);
if (stats.isFile() && isImage(file)) {
await processImage(filePath);
}
else if (stats.isDirectory()) {
await processDirectory(filePath);
}
}
}
This kind of code is the simplest to write, but it will execute everything "synchronously", in one long chain of IO calls.
To "fix" this, I could fan out to many hundreds of parallel "threads" by wrapping the files being processed into Promise.all() constructs. Like this:
async function processDirectory(path) {
const files = await fs.readdir(path);
await Promise.all(files.map(async file => {
const filePath = libPath.join(path, file);
const stats = await fs.stat(filePath);
if (stats.isFile() && isImage(file)) {
await processImage(filePath);
}
else if (stats.isDirectory()) {
await processDirectory(filePath);
}
}));
}
This seems better at a first glance, but is it really?
While parallelism might work great for network calls, not every IO operation is born equal. Disk operations, like in this case, will naturally want to be synchronous, as disk's head can only physically be at one position over the platter. This limitation seems to apply even to the current generation of SSD-s, although it might be lifted for the newer NVMe drives. So what's the point of parallelizing my code, if all my callbacks will get queued up in front of the disk anyway?
Then again, maybe it makes sense to queue up as many operations as I can, instead of calling back into javascript code between each read and letting the disk sit idly in the meantime.
I didn't know which was better, and couldn't find any articles analyzing this. So I decided to do an experiment.
The experiment
I started by making a program that works a bit like shell command du. It recursively goes through a directory tree, tallies up file sizes and prints out the final size at the end.
I implemented it a bit differently then the examples above. Instead of a naive "sync all" or "async all" loop, I made a queue system where I can precisely control the number of async "threads" at any point during the execution. Here is the slightly simplified code of the main function.
async function diskUsage(path, parallelism) {
const result = {
startedAt: new Date(),
completedAt: null,
size: 0,
};
let activeCount = 0;
const queue = [{path, exec: statOp}];
let resolveReject = {};
const resultPromise = new Promise((resolve, reject) => {
resolveReject = { resolve, reject };
});
Object.assign(resultPromise, resolveReject);
tick();
return resultPromise;
function tick() {
if (parallelism && parallelism <= activeCount) {
// We have to wait for something to finish
return;
}
if (!queue.length) {
if (activeCount) {
// There are some pending ops, but nothing in the queue yet. Wait a bit.
return;
}
// Nothing in the queue and no active ops. We are done.
result.completedAt = new Date();
resultPromise.resolve(result);
return;
}
// Launch the next task
const op = queue.pop();
activeCount++;
Promise.resolve()
.then(() => op.exec(op))
.catch(err => {
console.error(err);
})
.finally(() => {
activeCount--;
tick();
});
// Immediately try again
tick();
}
async function readOp({ path }) {
const files = await asyncReaddir(path);
for (const file of files) {
queue.push({path: libPath.resolve(path, file), exec: statOp});
}
}
async function statOp({ path }) {
const stats = await asyncStat(path);
if (stats.isDirectory()) {
queue.push({path, exec: readOp});
} else if (stats.isFile()) {
result.size += stats.size;
}
}
}
It's a pretty typical producer/consumer kind of system. readOp and statOp are the two kind of "ops" we can have in the queue. Main tick method pulls them out of the queue and runs them, according to the caller-provided parallelism parameter.
Then I wrote a CLI utility which calls this method with a sequence of different parallelism arguments and prints out the execution times in a table.
The results
I performed the experiment against my projects folder, with about 400K files, on a laptop SSD (not NVMe), with Ubuntu 20.04.
src/bin/experiment.js /path/to/my/projects/folder -p "1 2 3 4 5 7 10 15 20 30 50 100 200 500 1000 10000 100000 0"
Here is what I got:
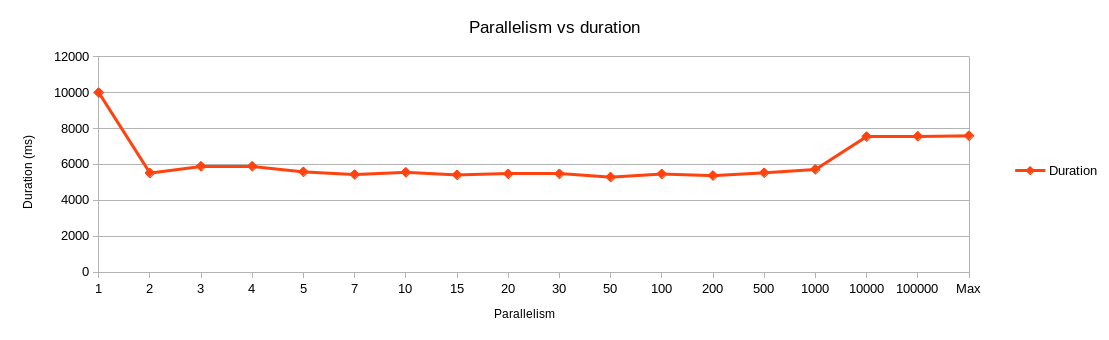
It seems that limiting parallelism to 1 is the worst case scenario. There is probably a lot of empty waiting time between one IO call ends and another begins. So some kind of parallelism is definitely a good idea.
Switching to 2 "threads" fixes the empty wait times, and we get from 10s down to the optimal time of around 6s. Adding more "threads" doesn't improve things further, which tells me the dumbest thing speculated is what actually happens. Disk will perform one read at a time, and any additional read requests will just queue up and wait their turn.
The surprising thing was that performance degraded to around 8s at parallelisms above 1,000. I am not sure why that is. Perhaps it hit some kind of memory limit, causing node to allocate more wait queues?
The conclusion
As suspected, you should never do an await in a loop, unless you know exactly what you're doing or performance isn't an issue.
For a quick naive solution, uncontrolled Promise.all fanning is good enough. It will properly fill up disk wait queue, which seems to be the main performance bottleneck for this use case.
For a top quality solution, you will want to control your fanning and prevent too many callbacks from clogging up the system. You could implement a job queue system, like above, or utilize some kind of async library, a la async.js (I wish I had a better recommendation here, but I usually just copy-paste my own job runner function between projects). If you can control parallelism, I'd go with about the number of CPU-s or double that. As long as you don't go over 1000 tasks, you should be good to go.
If you want to try out the experiment on your own hardware, the code is available on GitHub. I'd be particularly curious to see how this graph looks on an NVMe or some performance-based RAID, since I haven't had any of those available to test with.